






高阶网络的链接预测算法和应用
Hypergraph Neural Networks
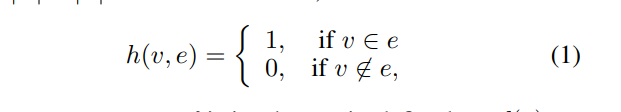
定义了超图的关联矩阵 H,其中 h(u,e) 是关联矩阵中的元素,它表示顶点 u 和超边 e 是否相关联。
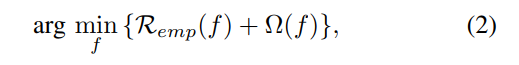
是节点(顶点)分类问题在超图上的正则化框架,这里 Ω(f) 是正则化项,Remp(f) 是经验损失项。
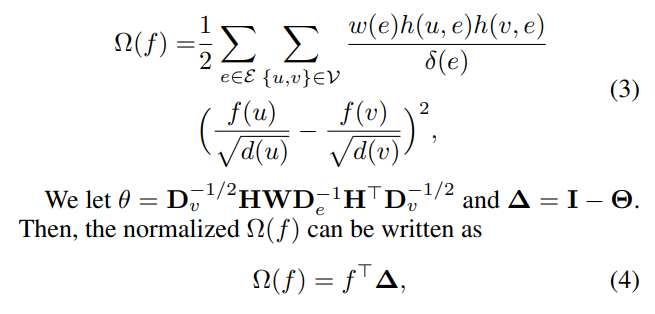
定义了正则化项Ω(f) 的具体形式,它是基于超图结构的一个正则化项,用于评估顶点之间的相似性。
描述了正则化项Ω(f) 的标准化形式,其中 Δ 是度矩阵 Dv 和 De 的逆矩阵乘以关联矩阵 H 和权重矩阵 W 的乘积再乘以关联矩阵的转置,这里 f^TΔ 实际上是拉普拉斯正则化项的一种形式。
超图卷积过程
-
顶点特征矩阵 :
- 初始维度:
- 描述: 包含图中每个顶点的特征向量。
-
顶点-超边关联矩阵 :
- 维度:
- 描述: 表明顶点和超边之间的关系。如果顶点 属于超边 ,则 ,否则为 0。
-
超边权重矩阵 :
- 维度:
- 描述: 对角矩阵,其中对角线上的元素表示每个超边的权重。
-
超边度矩阵 :
- 维度:
- 描述: 对角矩阵,其对角线上的元素表示每个超边连接的顶点数量。
-
顶点度矩阵 :
- 维度:
- 描述: 对角矩阵,其对角线上的元素表示与每个顶点相关联的所有超边的权重之和。
-
超边规范化:
- 计算:
- 结果维度:
-
超边规范化与超边度矩阵的逆平方根相乘:
- 计算:
- 结果维度:
-
顶点特征与规范化超边关联矩阵相乘:
- 计算:
- 结果维度:
-
顶点度矩阵的逆平方根与上一步结果相乘:
- 计算:
- 结果维度:
-
参数矩阵 :
- 维度:
- 描述: 包含卷积层中的可学习参数。
-
应用参数矩阵:
- 计算:
- 结果维度:
-
应用非线性激活函数 :
- 计算:
- 结果维度:
- 描述: 是卷积操作的输出,包含了更新后的顶点特征向量。
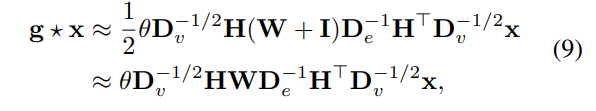
是高阶图卷积网络中的卷积操作的简化表达式,使用节点度矩阵和超边度矩阵。

定义了超图信号 X 的超边卷积,其中 Y 是卷积后的输出,W 是学习参数。
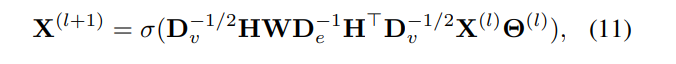
描述了超图神经网络中卷积层的更新规则
What Are Higher-OrderNetworks?
这篇综述文章讨论了复杂系统和数据的网络化建模,这在不同领域中已成为一个重要话题。

超图的定义

这部分文本定义了一个抽象的单纯复形),它是一种高阶网络结构,用于表示超图中的多元关系。
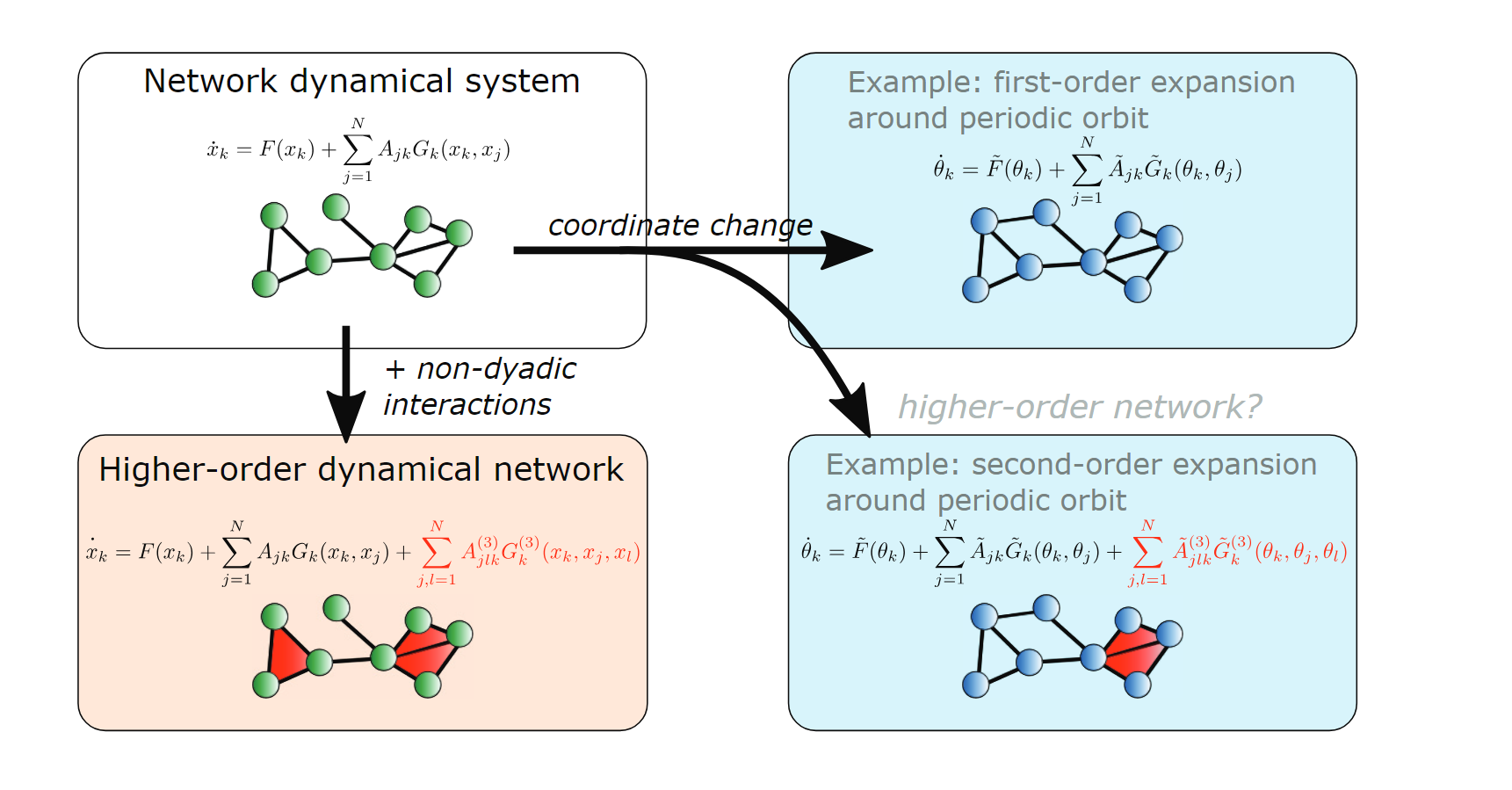
Simplicial closure and higher-order link prediction
这篇文章探讨了网络中的高阶交互(higher-order interactions)组织原则和时间演化。通过分析19个数据集,揭示了不同系统类型中高阶结构的一致模式。文章发现,联系强度(tie strength)和边缘密度(edge density)是高阶组织的正向指标。提出了高阶链接预测(higher-order link prediction)作为基准问题,评估预测高阶结构的模型和算法,发现与成对链接预测相比,本地信息在预测新交互时比远程信息(深层信息)更为重要。
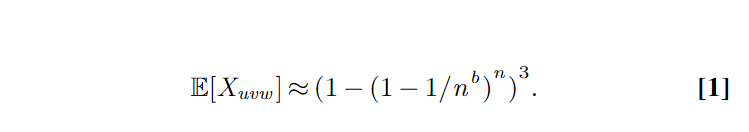
是一个指示随机变量,表示节点 u, v, 和 w 形成一个开放三角形的情况。、
模型可以用来生成具有特定三角形分布特性的网络数据集,进而用于研究和模拟真实世界网络的结构和动态。
Link prediction in complex networks based on Significance of Higher-Order Path Index (SHOPI)
这篇文章提出了一个新的相似性指数SHOPI,用于链接预测,通过惩罚共同邻居来限制信息泄露,并利用高阶路径(Higher-Order Paths)作为区分特征。SHOPI在12个真实网络数据集上的实验结果显示,它优于基线方法,与现有的Katz指数和本地路径指数(Local Path Index, LP)相比更为稳健。这与高阶网络的研究相关,因为它考虑了高阶路径作为连接预测的特征。

- 初始化阶段 :
- prev和 score两个矩阵被初始化为零矩阵。
- 对于图中的每一对节点 (i, j),计算二阶路径(两步可达)的得分。
- z 是节点对 (i, j) 的共同邻居。
- score[i, j] 被设置为 1/kz,其中 kz 是节点 z 的度数,即与 z 相连的边数。
- prev[i, j] 用来存储上一次迭代的得分。
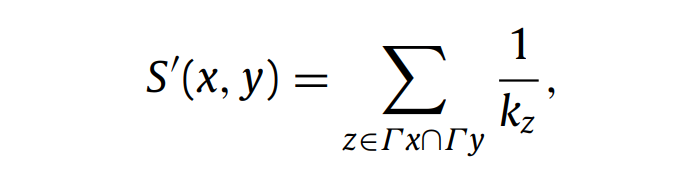
- 计算阶段 :
- l 表示路径长度,lmax 是最大考虑的路径长度。
- temp 矩阵被初始化,用来临时存储计算结果。
- 对于每一对节点 (i, j),对于节点 i 的每个邻居 Ni,计算由节点 i 到 Ni 的路径得分 f1,以及 Ni 到 j 的上一次迭代得分 f2。
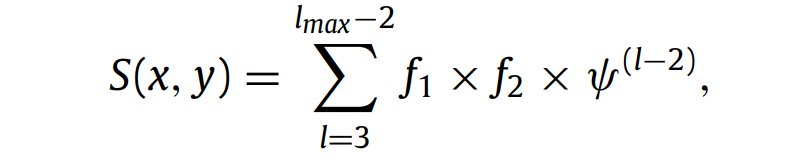
- temp[i, j] 通过 f1 * f2 * ψ^(l-2) 更新,其中 ψ 是惩罚参数,用于减少通过共同邻居泄漏的信息量。
- 更新阶段 :
- 更新 score 矩阵,将 temp 矩阵中计算的得分加到 score[i, j] 上。
- 将 prev 矩阵更新为 temp 矩阵的内容,为下一次迭代做准备。
最终,算法返回 score 矩阵,包含所有节点对的相似度得分。
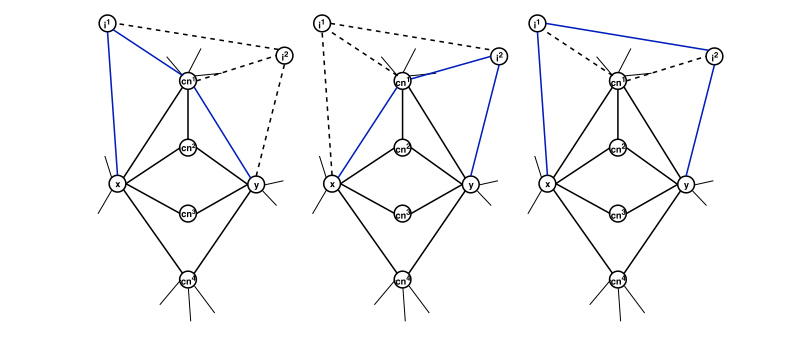
在这篇文章中,“高阶”指的是考虑节点对之间通过多个中间节点连接的路径,而不仅仅是直接的连接或共同邻居。
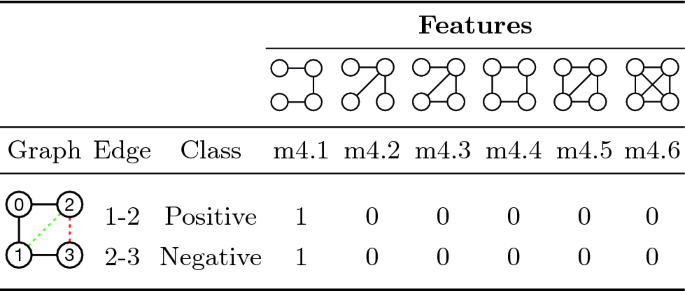
Link Prediction via Higher-Order Motif Features
这篇文章提出了一种基于高阶拓扑分析的链接预测方法,超越了依赖共同邻居的传统方式。将链接预测视为监督分类问题,并引入依赖于节点对出现的模式或动机(motifs)的特征集,特别是k = 3、4、5的模式。此外,文章还提出了两种优化构建分类数据集的方法:一是向图中添加负例,二是控制采样节点对形成负例时的最短路径距离。实验表明,使用所提动机特征可显著提高分类准确率,与高阶(higher-order)关系在于使用了图中更复杂的结构模式来提高预测性能。
- 对于分类数据集中的每个边示例(无论是正例还是负例),算法会枚举该边参与的所有k-motif
- 计算每种不同motif的出现次数。这些计数结果构成了用于训练分类器的特征向量。
- 分类器学习这些特征与边存在与否之间的关系,从而用于预测未知边。
通过这种方法,分类器能够利用复杂的拓扑特征来提高预测的准确性。
Graph embedding-based novel protein interaction prediction via higher-order graph convolutional network
这篇文章提出了一种新的节点(蛋白质)嵌入方法,结合图卷积网络GCN和PageRank,用于蛋白质-蛋白质互作(PPI)网络中新链接的预测。通过开发高阶GCN变分自编码器(HO-VGAE)架构,实现了基于更高阶局部和全局PPI网络拓扑的节点表示学习,无需额外的生物学特征。这与高阶(higher-order)关系紧密,因为它扩展并探索了节点的高阶邻域拓扑信息。
模型由两部分组成:编码器和解码器。编码器使用高阶GCN生成潜在节点嵌入,这些嵌入遵循高斯分布。解码器部分使用这些潜在嵌入来重建输入的网络结构,目的是重构PPI网络并发现新的蛋白质相互作用。模型通过最小化重建误差和Kullback-Leibler(KL)散度来训练,以学习低维且稳定的节点表示,从而预测新的相互作用。
- 公式 (1): 这是节点嵌入的非线性激活函数,使用ReLU作为激活函数,它作用于每个卷积层的传播结果。
$ Z^{l+1} = \text{ReLU}(H{l}W{l}) $ - 公式 (2): 表示了每个卷积层中用于随机游走或传播的幂迭代计算。这里结合了图传播效应和PageRank的概念。
$ H^{l}{k+1} = (1 - \alpha)A{\text{norm}}H^{l}_{k} + \alpha Z^{l} $ - 公式 (3): 初始化幂迭代过程中 $ H^{l} $ 的值。
$ H^{l}_{0} = Z^{l} $ - 公式 (4): 当 $ k $ 趋向于无穷大时,幂迭代会收敛,这时 $ H^{l}{k+1} $ 可以用 $ H^{l}{\infty} $ 来近似表示,进而得到收敛的公式。
$ H^{l}{\infty} = \alpha(I_n - (1 - \alpha)A{\text{norm}}){-1}Z{l} $ - 公式 (5): 高阶GCN中节点嵌入的非线性激活函数,这是使用了得分矩阵 $ S Z^{l+1} = \text{ReLU}(SZ{l}W{l}) $
- 公式 (6): 高阶GCN模型的最终输出,代表了通过 $ L $ 层卷积计算后得到的节点嵌入。
$ \text{GCN}(X, A) = Z^{L} $

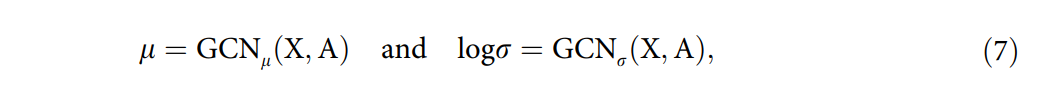
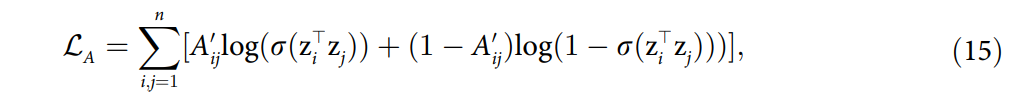
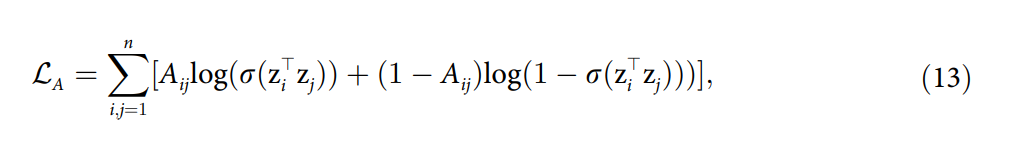
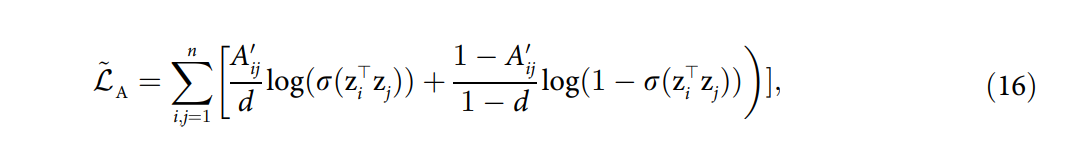
Higher-Order Relations Skew Link Prediction in Graphs
这篇文章探讨了在存在高阶关系的情况下,链接预测问题的表现。研究发现,常见邻居启发式方法在高阶关系中表现得非常好。然而,文章证明了这是因为CN在高阶关系中过高估计了其预测能力。通过考虑高阶关系的理论模型,并显示CN的AUC分数高于模型所能达到的水平,来证明这一点。文章还扩展了对其他类似链接预测算法(如Adamic Adar)的观察,并提出了一个调整因子以更好地估计泛化分数,关于高阶(higher-order)的关系在于它调查了CN启发式方法在考虑高阶关系时的表现和理论基础。
文章通过计算AUC(曲线下面积)分数来评估常见邻居方法的性能,并指出在高阶关系存在的情况下,CN方法的AUC分数高于理论模型所能达到的最高分数。基于上述观察,文章提出了一个调整因子,用于修正预测分数,使其更好地估计算法在不同网络结构中的泛化能力。

对于给定的顶点子集 f,如果存在潜在空间 Rd 中的球体,使得 f 中所有顶点的潜在向量都包含在球体内,则 f 可以成为一个潜在的超边。
Higher-Order Temporal Network Prediction
这篇文章提出了一个基于记忆的模型,用于预测未来一步的高阶时间网络(或事件),这种网络记录了随时间发生的高阶事件。与传统的时间网络预测方法相比,该模型能够更好地预测高阶交互,并且在八个真实世界网络中表现优于基线模型。这个模型利用了网络过去观察到的活动,将高阶时间网络预测问题视为一个监督学习问题。模型假设一个群组在下一个时间步的活动受到该目标群组及其子群组和超群组过去活动的影响,且近期事件的影响大于旧事件。通过考虑不同大小的超链接(hyperlinks)及其活动状态,模型能够预测未来的高阶交互活动。此外,文章还提出了一个基线模型,将过去观察到的高阶时间网络视为成对时间网络,并从预测的成对交互中推断出高阶交互。实验结果显示,该模型在多个真实世界的网络数据集中均优于基线模型。
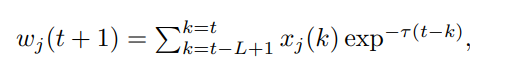
t + 1是预测的时间步长,L是用于预测的过去观测的长度,τ是指数衰减因子,xj(k)是时间k时链接j的激活状态:如果链接j在时间k处于活跃状态,则xj(k) = 1,否则xj(k) = 0。
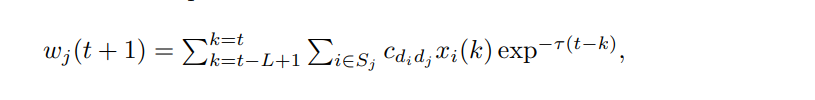
其中L是过去用于预测的网络观察的时间长度,τ是指数衰减因子,Sj是超链接j的子超链接或超超链接的集合,xi(k)是时间k时超链接i的激活状态。cdidj是交叉阶影响系数,其中di是超链接i的大小,dj是超链接j的大小。例如,c32是与激活一个3超链接对其大小为2的子超链接的激活影响相关的系数。我们对任意大小d的超链接,都将cdd设为1。通过变化交叉阶系数cd1d2(对于d1 ≠ d2)的值,我们可以得到我们一般模型的不同子模型。
Tackling higher-order relations and heterogeneity: Dynamic heterogeneous hypergraph network for spatiotemporal activity prediction
这篇文章提出了一个动态异构超图网络模型,用于时空活动预测。这个模型使用超图来更好地建模高阶关系,并通过一个灵感来自集合表示学习的异构超边学习模块来处理时空活动预测中的高阶关系和异质性。此外,还引入了一个知识表示正则化损失来改进异质时空活动超边的编码,并提出了一个超图结构学习模块来动态更新超图结构。该模型在四个真实世界数据集上的测试表明,其性能超过了当时的最先进方法。
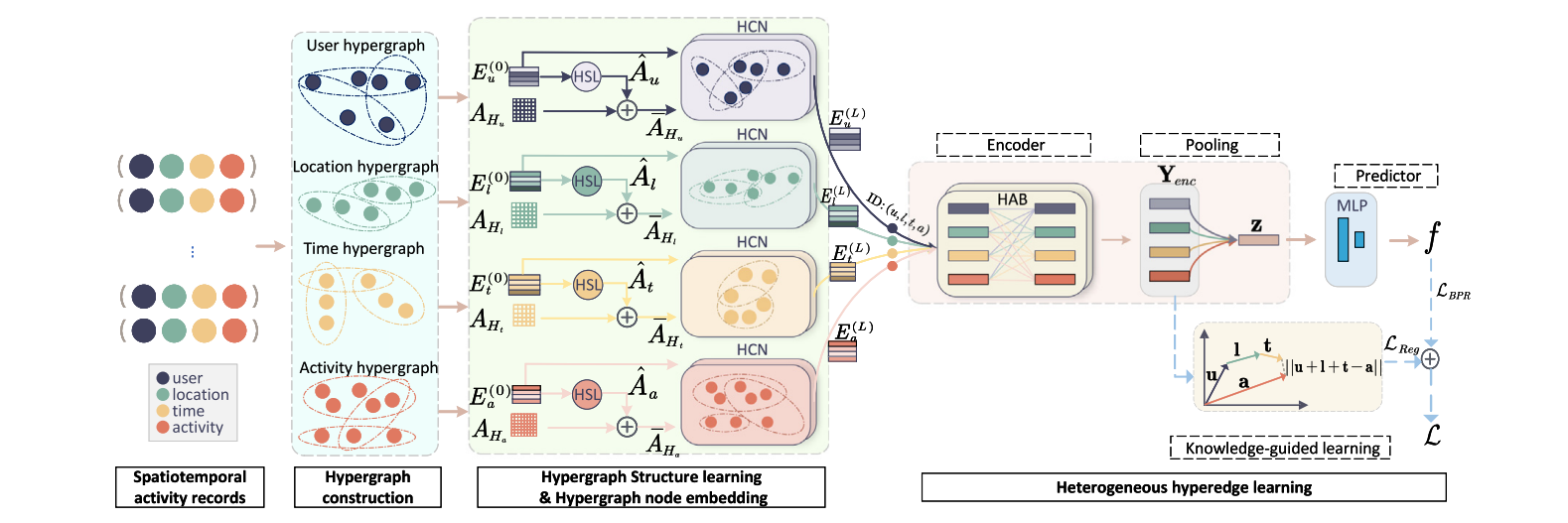

- 结构学习 :
- 对每种模态的节点嵌入应用结构学习算法,得到更新的结构矩阵Au、Al、At、Aa。
- 结构更新 :
- 结合初始超图结构AH和学习到的结构矩阵A^(i)来更新超图结构A~H。
- 迭代节点嵌入 :
- 对于i从1到L(L层的深度),更新节点嵌入E^(i) = A~H * E^(i-1)。
- 聚合节点嵌入 :
- 通过计算所有层次的节点嵌入的均值来聚合节点嵌入,得到E。
- 生成嵌入向量 :
- 对于每个活动记录(u, l, t, a),从嵌入矩阵E中提取相应的用户、地点、时间和活动的嵌入向量。
- 嵌入表示转换 :
- 将用户、地点、时间和活动的嵌入向量合并成一个嵌入矩阵X ∈ R^4xd。
- 编码嵌入矩阵 :
- 使用Hyperedge Attention Block(HAB)对嵌入矩阵X进行两次处理,得到Y_enc。
- 池化操作 :
- 对编码后的嵌入矩阵Y_enc应用池化操作,得到向量表示z。
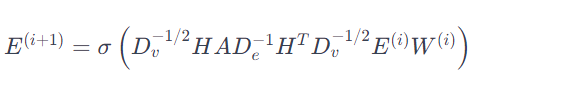
原论文对HCN定义

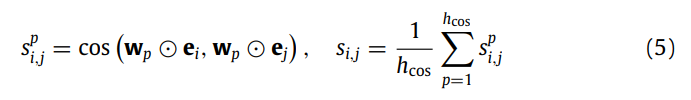
用于计算节点嵌入之间的加权余弦相似性。

描述了邻接矩阵的稀疏化过程,通过设置一个阈值 ϵ 来删除小于该阈值的相似性分数,从而减少连接。

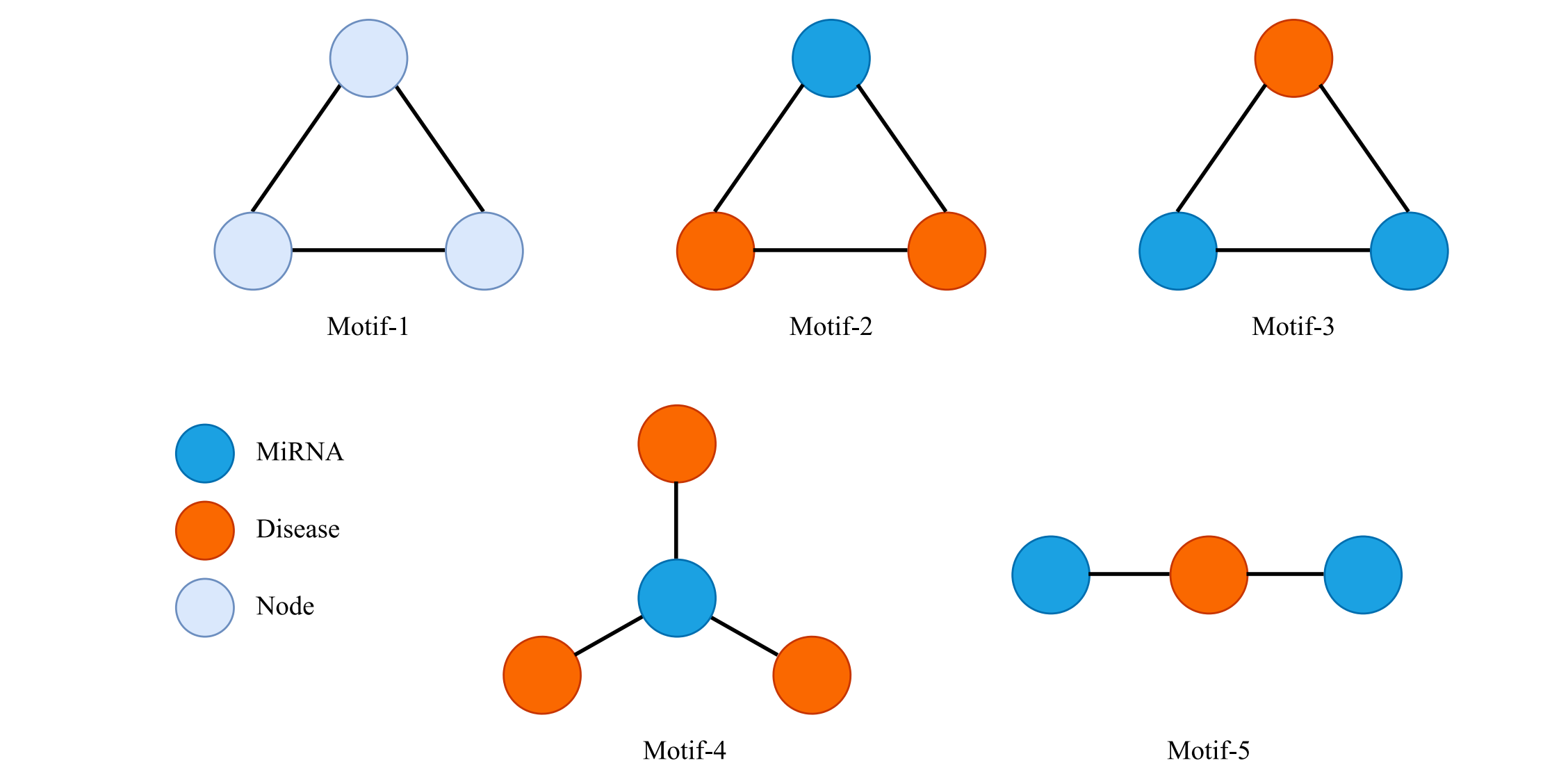
Incorporating higher order network structures to improve miRNA–disease association prediction based on functional modularity
这篇文章旨在通过整合更高阶的网络结构来提升miRNA-疾病关联(MDAs)的预测性能。该模型首先整合了miRNA相似性网络、疾病相似性网络和MDA网络,然后识别出重叠的功能模块,并设计了一种基于路径的评分函数来推断潜在的MDAs。HiSCMDA在跨验证和独立验证实验中表现优异,特别是在对结肠肿瘤和肺肿瘤的预测中,获得了数据库验证的高准确率。
该网络定义了五种不同的高阶模式(motifs),用于预测新的miRNA-疾病关联(MDAs)。
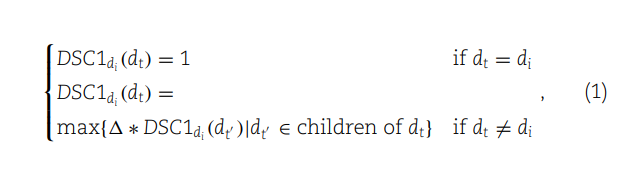
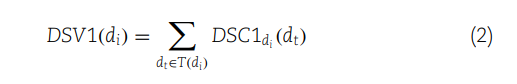
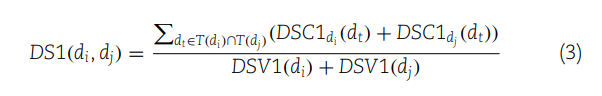
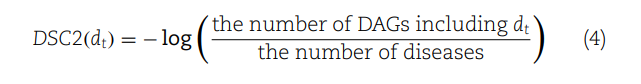
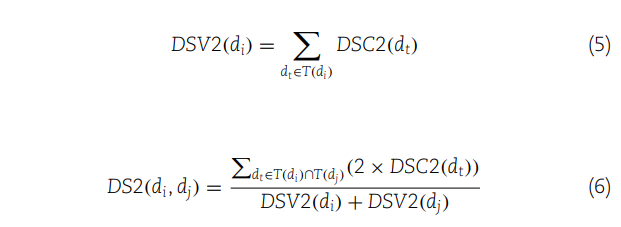
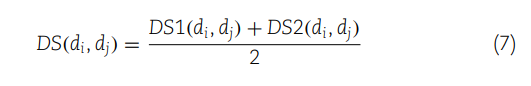
(1) 定义了疾病在DAG中的语义贡献度。如果两种疾病相同,其贡献度为1;如果不同,则取决于它们的关系,通过其子节点的最大语义贡献度与一个衰减因子的乘积来计算。
(2) 计算了一个疾病的所有祖先节点的语义贡献度之和,从而得出该疾病的语义值(DSV1)。
(3) 使用疾病的DAG中共有的祖先节点的语义贡献度,来计算两种疾病间的第一种语义相似性(DS1)。
(4) 提供了另一种方法来计算疾病在DAG中的语义贡献(DSC2),这次是通过考虑疾病在多少个DAG中出现。
(5) 计算了疾病所有祖先节点的第二种语义贡献度之和,从而得出该疾病的第二种语义值(DSV2)。
(6) 利用第二种语义贡献度来计算两种疾病间的第二种语义相似性(DS2)。
(7) 最后,通过取两种语义相似性度量(DS1和DS2)的平均值,来计算两种疾病间的综合语义相似性(DS)。
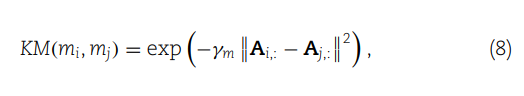
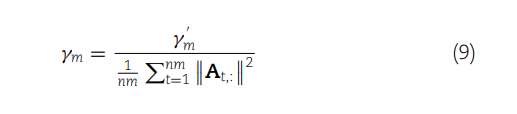
(8) 定义了两个miRNAs之间的高斯核相似度,它基于它们的交互作用轮廓(例如,与疾病的关联)。这个相似度通过计算两个miRNAs交互作用轮廓之间的欧氏距离的指数负值来得到,其中 γm 是核宽度的调节参数。
(9) 给出了如何计算 γm,即通过所有miRNAs交互作用轮廓的平均欧式距离的倒数。
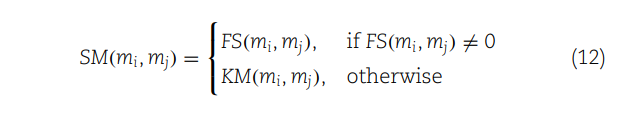

(12) 定义了miRNAs之间的集成相似性(SM)。如果两个miRNA之间的功能相似性(FS)不为零,就使用FS值;如果FS为零,则使用高斯交互轮廓核相似性(KM)。
(13) 引入了一个相似性矩阵 F,用于表示miRNA相似性网络。每个元素 Fij 只有在 SM(mi,mj) 大于或等于给定阈值 β 时,否则为0
SD逻辑相同
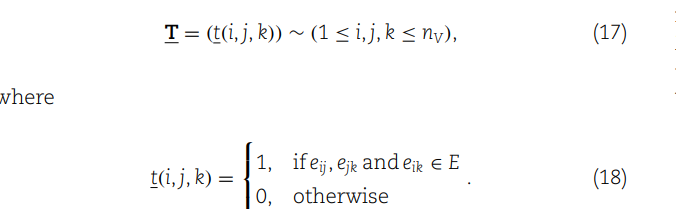
高阶网络不同motif定义
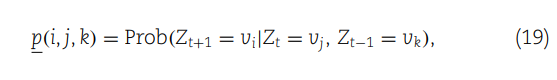
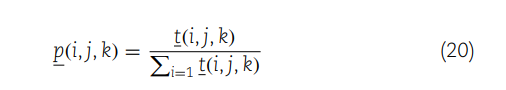
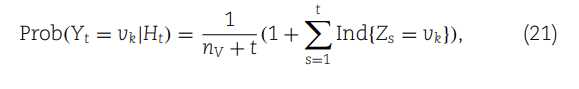
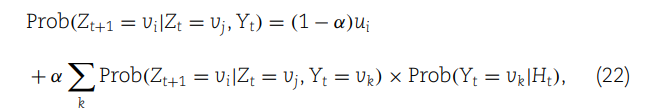
这部分内容在网络模型中引入了复杂的转移概率计算,以及如何利用这些信息来检测可能在miRNA和疾病之间的关联模式。
STHGCN: A spatiotemporal prediction framework based on higher-order graph convolution networks
这篇文章提出了一个名为STHGCN的新的时空预测框架,核心思想是利用高阶依赖性来建模时空依赖性。具体来说,对于时空维度,提出并实现了一个高阶时间差分网络和一个高阶空间语义图卷积网络(GCN)。实验结果表明,STHGCN优于现有的最先进的时空预测模型。这与高阶(higher-order)关系密切相关,因为该模型通过高阶依赖性来精确捕获时空数据的复杂关联。

动态关系指的是那些随着样本X的变化而变化的空间依赖性。不同于静态关系,在模型学习完成后不再需要改变,动态关系会随样本X在STHGCN模型中的变化而变化。
- 初始化源节点嵌入E1和E2,并计算静态关系邻接矩阵As。
- 将动态关系邻接矩阵Ad附加到A。
- 根据公式计算动态关系邻接矩阵Ad、概率p(r|θ, X)、均值µ(X)和标准差σ(X)。
- 存在预定义的图邻接矩阵Ae,则A = [Ae, As, Ad];否则A = [As, Ad]。
- 对于l=1到L(网络深度),
- 根据公式计算X_T^(l)。
- 计算X^(l+1)。
- 根据公式计算最终输出Ŷ。
- 根据公式计算最终损失L。
Prompt learning
综述
Prompt learning通常是在预训练的语言模型(如BERT)的基础上,通过设计一个或一系列的提示语句,引导模型根据给定的上下文完成特定的任务,比如语句填空、分类、生成等。这种方法可以有效利用预训练模型的语言理解能力,通过少量的调整来适应新的任务或数据集。
Learning Transferable Visual Models From Natural Language Supervision
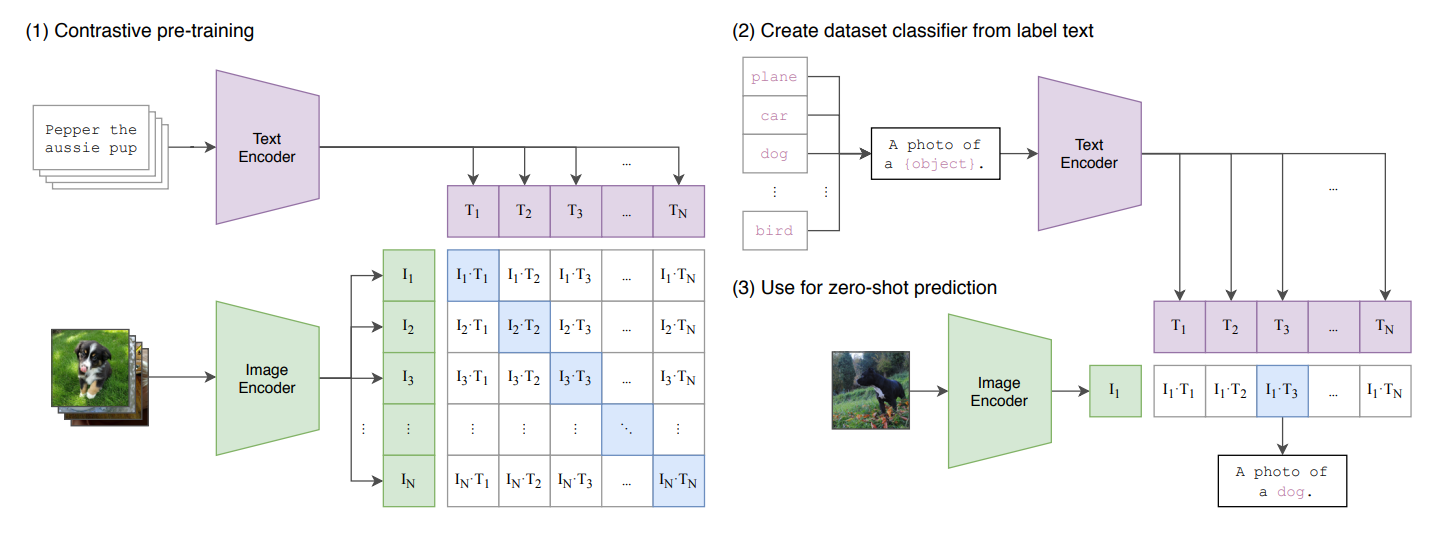
在Zero-Shot学习中,图像编码器没有直接学习特定任务的样本,但理解图像编码器和文本编码器在预训练阶段是如何一起学习的,编码器学习了如何将文本和图像映射到同一个嵌入空间,并确保相关的图像和文本对彼此接近。这种学习是在大量的图像和文本对上进行的,使得模型学会了理解各种各样的视觉和文本信息。
模型预测不是随机选择一个标签。相反,它利用预训练期间学到的图片转换为的文本特征表示来进行推理。模型理解了很多不同的图像特征和关联的文本描述,即使它没有直接学习过新的特定样本,也能使用这些通用的表示来推断新样本最可能关联的文本描述。
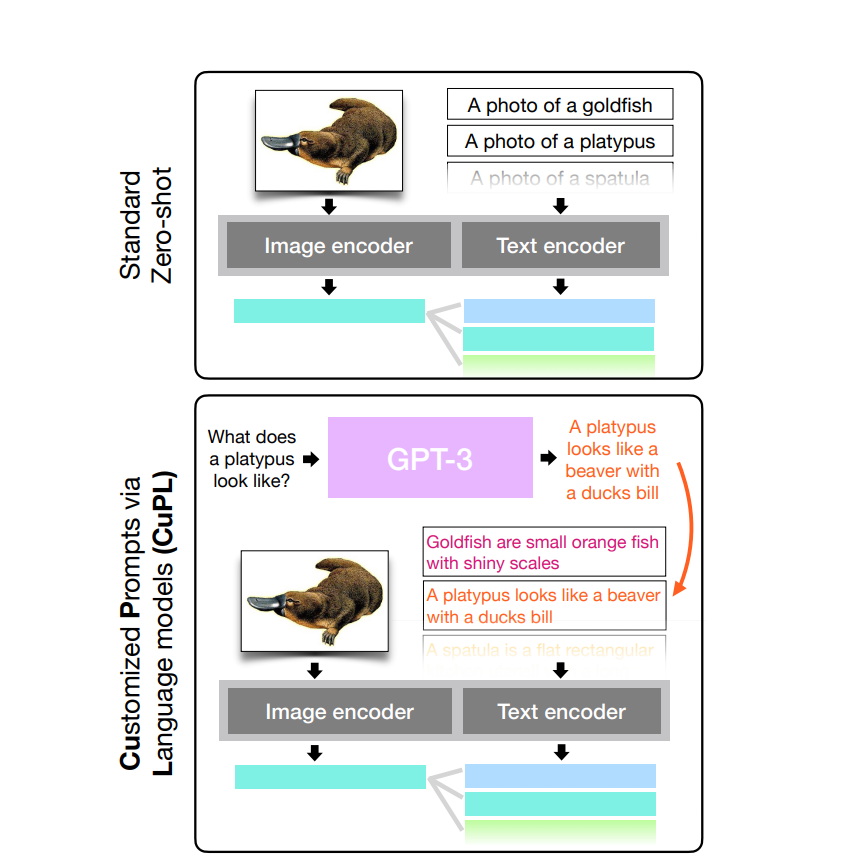
What Does a Platypus Look Like? Generating Customized Prompts for Zero-Shot Image Classification
这篇论文提出的基线方法是结合开放词汇模型和大型语言模型(LLM)来生成定制化提示(CuPL),用于图像分类。首先,LLM生成描述图像类别的详细描述,这些描述随后作为提示用于开放词汇模型进行图像分类。这一过程不需要额外的训练,在多个基准测试中提高了准确性。
图像分类模型通常是通过结合视觉模型和文本模型来处理的,例如使用多模态学习方法。在这种情况下,图像和生成的文本提示同时作为输入,模型学习如何结合这两种形式的信息来进行分类。

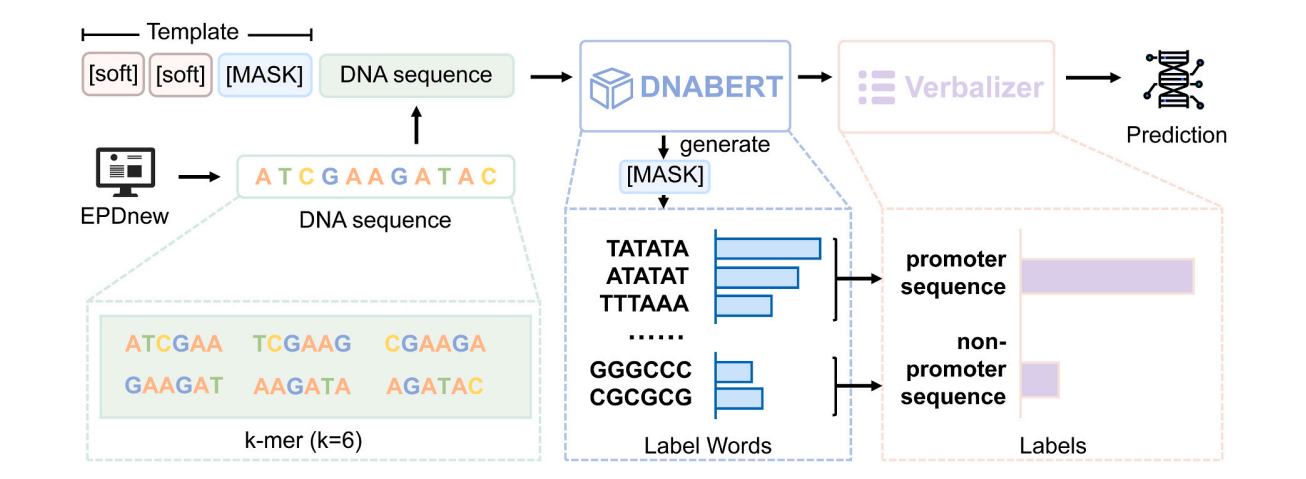
PLPMpro: Enhancing promoter sequence prediction with prompt-learning based pre-trained language model
研究引入了PLPMpro模型,该模型结合了prompt-learning和预训练语言模型,用于提高启动子序列(promoter sequences)的预测准确性。该模型不仅超越了典型的基于预训练模型的启动子预测方法,也超越了典型的深度学习方法。此外,通过各种实验详细考察了不同prompt learning设置和不同数量的软模块(soft modules)对模型性能的影响。更重要的是,解释实验揭示了预训练模型捕获了生物学语义。
DNA序列被转换成6-mer序列,并与prompt模板(包含soft modules和[MASK])结合。然后,这些带有模板的DNA序列被输入到DNABERT模型中,DNABERT生成填充在[MASK]中的所有可能词汇的概率。接着,使用verbalizer将生成的词汇概率映射到不同标签的概率上
Universal Prompt Tuning for Graph Neural Network
这篇文章提出了一种通用的基于提示的调整方法,名为图提示特征(Graph Prompt Feature, GPF),适用于任何预训练策略下的图神经网络(GNN)模型。与传统的针对特定预训练任务设计的提示函数不同,GPF在输入图的特征空间上操作,理论上可以达到任何形式的提示函数的效果,从而避免了为每种预训练策略显式定义提示函数的需要。GPF通过适应性地获取针对下游任务的提示图,展示了其在多种预训练策略下的普适性和有效性,实验结果显示GPF在全量和少量标注场景下均优于传统的微调方法,为下游任务的适应提供了一个有力的替代方案。与Prompt learning的关系在于,GPF利用了提示学习的理念,通过引入图特征空间中的提示来改善预训练GNN模型在特定下游任务上的性能。
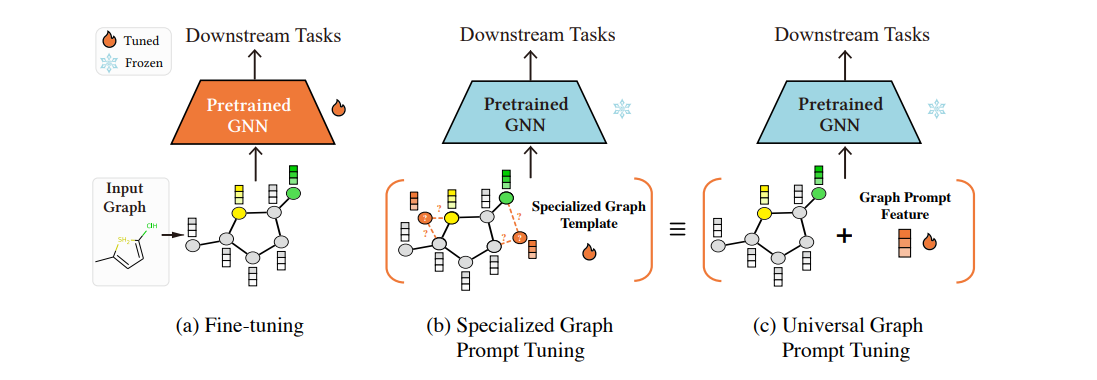
我们可以向分子图的特征空间引入提示,例如增加与特定化学功能相关的节点或边的特征权重,从而帮助预训练的GNN模型更好地识别和区分具有不同化学性质的分子。这种提示可以是基于已知化学规则的特征增强,或者是通过学习得到的针对特定化学任务的特征表示。
这些自定义的提示特征权重通常来源于对特定任务的先验知识或通过对数据集的探索性分析获得的洞察。在某些情况下,这些权重也可以通过自动化的搜索和优化过程获得,其中机器学习算法试图找到最佳的特征权重组合,以提高模型在下游任务上的性能。这个过程与模型的初始预训练状态无关,但旨在增强模型对特定任务的适应能力。
GPL-GNN: Graph prompt learning for graph neural network
这篇文章提出了一个名为GPL-GNN的新框架,用于解决在有限标注数据下,图表示学习性能瓶颈的问题。GPL-GNN通过将无监督预训练的结构表示作为提示信息引入下游任务,以缩小预训练目标与下游任务之间的差距。这种方法不仅提高了模型对特定任务的适应性,还增加了选择任务特定GNN模型的灵活性。此外,引入原型网络(prototype networks)作为分类头,实现了对下游任务的快速适应。
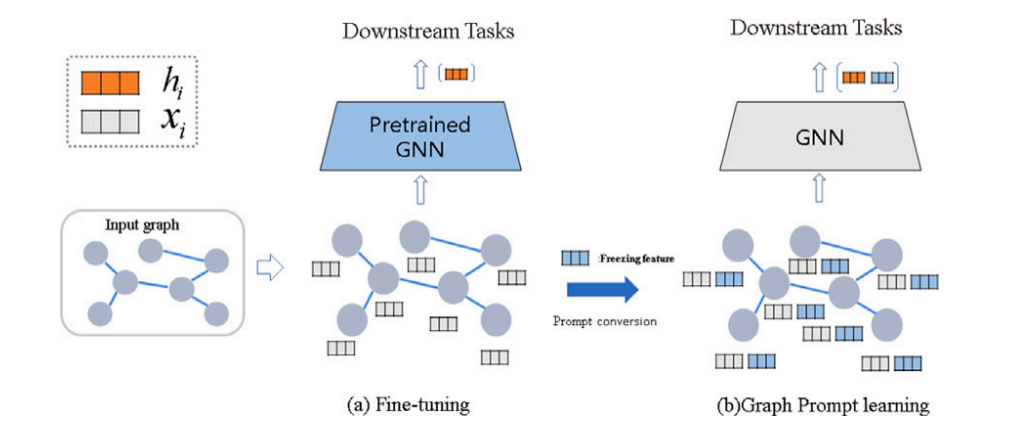
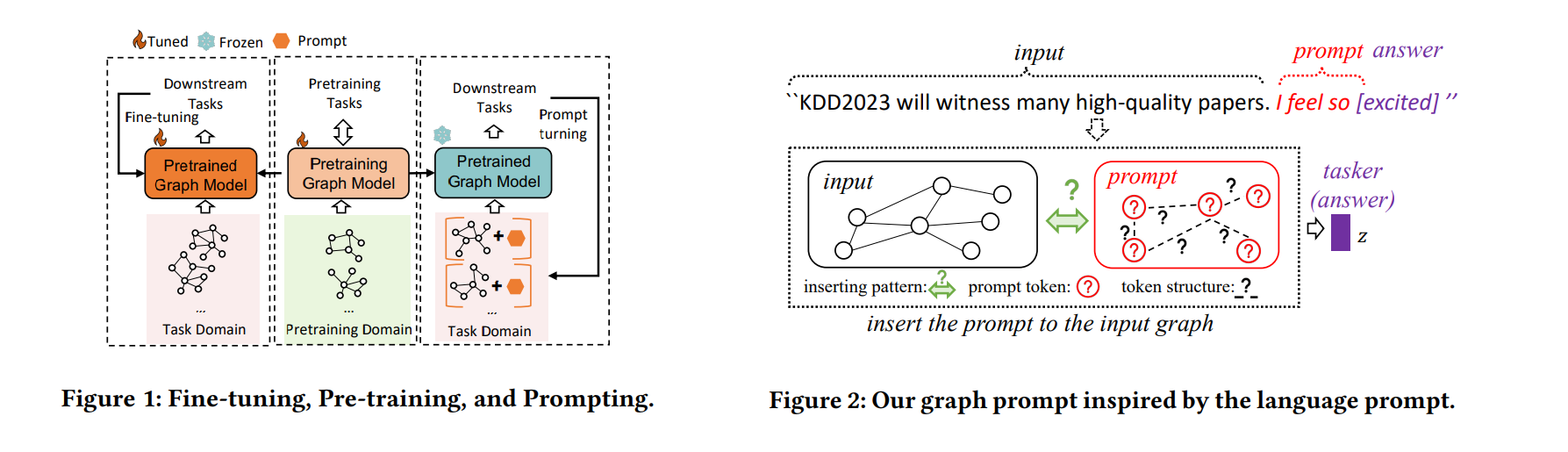
All in One: Multi-Task Prompting for Graph Neural Networks
这篇文章提出了一种新的多任务图提示方法,旨在缩小预训练模型与多种图任务之间的差距,通过设计一种特殊的图提示结构来统一图提示和语言提示,这种结构将NLP中的提示概念与图数据相结合。具体来说,它在图的节点或边特征中插入预定义或可学习的提示标记,类似于NLP中向文本序列中添加特定词汇或短语的做法。这些图提示模拟语言提示的作用,引导图神经网络模型更好地理解和执行特定的下游任务。
GNN数据集
Cora
每行(图的一个节点)的第一个字段是论文的唯一字符串标识,后跟 1433 个字段(取值为二进制值),表示1433个词汇中的每个单词在文章中是存在(由1表示)还是不存在(由0表示)。最后,该行的最后一个字段表示论文的类别标签(7个)。因此该数据的特征应该有 1433 个维度,另外加上第一个字段 idx,最后一个字段 label, 一共有 1433 + 2 个维度。
Citeseer
共包含3312篇论文,记录了论文之间引用或被引用信息。去除停用词和在文档中出现频率小于10次的词,整理得到3703个唯一词。CiteSeer数据集包含两个文件:.content文件和.cites文件:.content文件描述论文信息的格式为:<paper_id> <word_attributes>+<class_label>;每行的第一个条目(paper_id)是每篇论文的唯一编号ID,后续(word_attributes)包含3703个二进制码,表示词汇表中的每个单词在论文中是否存在(由1表示)或不存在(由0表示),最后一个条目(class_label)表示论文的类标签。.cites文件描述了论文之间的引用信息,格式为: 。每行数据包含了两篇论文的编码ID,第一个条目(ID of cited paper)表示被引用论文的编号,第二个条目(ID of citing paper)表示引用论文的编号。Citeseer数据集被广泛应用于节点分类、引文关系分析和文献推荐等任务。
PubMed
PubMed数据集中的文献包含了丰富的特征信息,如标题、摘要、作者、关键词等。此外,数据集还提供了文献之间的引用关系,可以用于分析文献之间的相互引用和关联性。对于图神经网络(GNN)的研究,PubMed数据集被广泛应用于节点分类、文献关系分析和知识图谱构建等任务。通过使用GNN模型,可以根据文献的特征和引用关系来预测文献所属的类别(如疾病、基因或化学物质),探索文献之间的相似性和相关性,以及构建生物医学知识图谱。
Reddit数据集是一个用于社交网络分析和挖掘的常见数据集,包含了来自不同社区的用户以及他们之间的交互关系。这个数据集通常被用来进行社区发现、用户分类、推荐系统等任务。
PPI
这个数据集包含了不同蛋白质之间相互作用的信息,对研究蛋白质结构和功能具有重要意义,在PPI数据集中,通常会包含已知的蛋白质相互作用关系,这些关系可以描述为一个由节点和边组成的图。其中,图的节点代表不同的蛋白质,而图的边则表示蛋白质之间的相互作用关系。对于图神经网络(GNN)的研究,PPI数据集被广泛应用于预测新的蛋白质相互作用、研究蛋白质网络的拓扑结构、发现蛋白质功能模块等任务。通过使用GNN模型,可以利用蛋白质的结构特征和相互作用关系来预测未知的蛋白质相互作用,探索蛋白质网络的特性和功能,以及发现潜在的生物学规律。
Amazon
Amazon Computers and Amazon Photo are segments of the Amazon co-purchase graph [McAuley et al., 2015],
https://arxiv.org/pdf/1506.04757.pdf
论文作者主页提供的原始数据集 https://cseweb.ucsd.edu//~jmcauley/datasets.html
原始数据集是为推荐任务做的,几百万个结点。
分子数据集
BBBP
血脑屏障渗透(渗透性)的二进制标记
num:编号
name:化合物名称
p_np:渗透/非-渗透的二值表示
smiles:分子结构
clintox、HIV、muv等等
蛋白质数据集
- HI-II-14 数据集:由二元管道获得的系统PPI网络。
- HI-III 数据集:通过高通量实验筛选技术生成的PPI数据。
- Lit-BM-13 数据集:文献整理的直接物理相互作用的PPI网络。
- BioGRID 数据集:涵盖生物分子相互作用的数据库。
- Bioplex 数据集:共复合物蛋白质组学数据集。
- Hein et al 数据集: